OpenAI 宣布开源多语言语音识别系统 Whisper,会有哪些改变?
自己测试了一下,效果特别好。一键调用,特别简单。开源还多语言,会冲击到各种商业化的语音识别服务。
github: GitHub - hyperoslo/Whisper: Whisper is a component that will make the task of display messages and in-app notifications simple. It has three different views inside
Whisper 是一个自动语音识别 (ASR) 系统,它使用从网络上收集的 680,000 小时多语言和多任务监督数据进行训练。我们表明,使用如此庞大且多样化的数据集可以提高对口音、背景噪音和技术语言的鲁棒性。此外,它还支持多种语言的转录,以及将这些语言翻译成英语。我们是开源模型和推理代码,可作为构建有用应用程序和进一步研究稳健语音处理的基础。
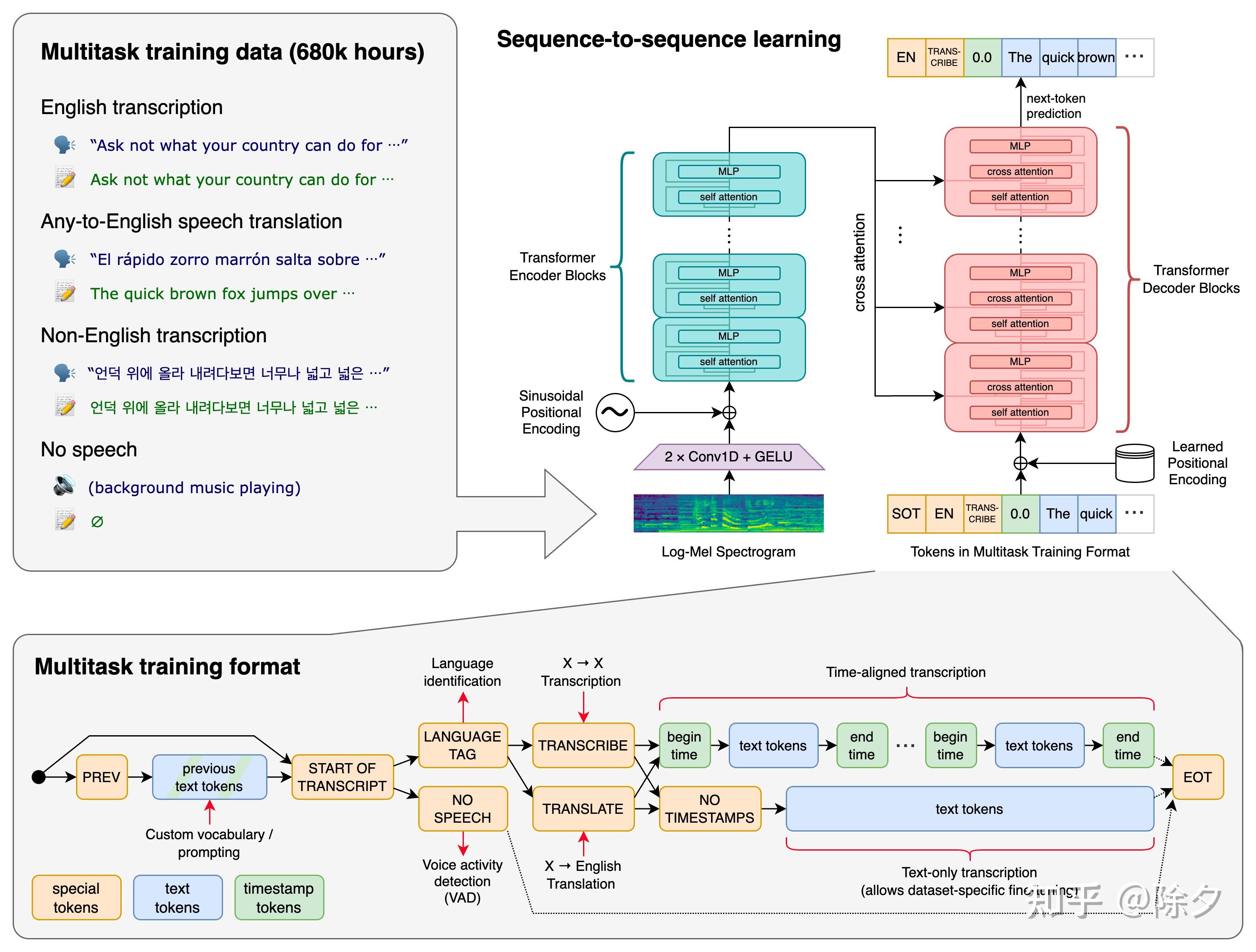
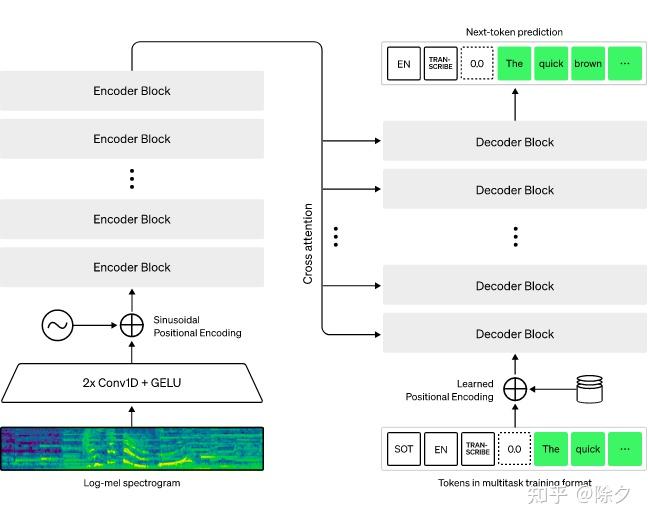 Whisper 架构是一种简单的端到端方法,实现为编码器-解码器 Transformer。输入音频被分成 30 秒的块,转换成 log-Mel 频谱图,然后传递到编码器。解码器被训练来预测相应的文本标题,并与特殊标记混合,这些标记指导单个模型执行诸如语言识别、短语级时间戳、多语言语音转录和英语语音翻译等任务。
Whisper 架构是一种简单的端到端方法,实现为编码器-解码器 Transformer。输入音频被分成 30 秒的块,转换成 log-Mel 频谱图,然后传递到编码器。解码器被训练来预测相应的文本标题,并与特殊标记混合,这些标记指导单个模型执行诸如语言识别、短语级时间戳、多语言语音转录和英语语音翻译等任务。
 其他现有方法经常使用更小、更紧密配对的音频文本训练数据集,1 2 3或使用广泛但无监督的音频预训练。4 5 6因为 Whisper 是在一个庞大而多样的数据集上训练的,并且没有针对任何特定的数据集进行微调,所以它不会击败专门研究 LibriSpeech 性能的模型,这是一个著名的语音识别竞争基准。然而,当我们在许多不同的数据集上测量 Whisper 的零样本性能时,我们发现它比那些模型更加稳健,并且错误率降低了 50%。
其他现有方法经常使用更小、更紧密配对的音频文本训练数据集,1 2 3或使用广泛但无监督的音频预训练。4 5 6因为 Whisper 是在一个庞大而多样的数据集上训练的,并且没有针对任何特定的数据集进行微调,所以它不会击败专门研究 LibriSpeech 性能的模型,这是一个著名的语音识别竞争基准。然而,当我们在许多不同的数据集上测量 Whisper 的零样本性能时,我们发现它比那些模型更加稳健,并且错误率降低了 50%。
Whisper 的音频数据集大约有三分之一是非英语的,它交替执行以原始语言转录或翻译成英语的任务。我们发现这种方法在学习语音到文本的翻译方面特别有效,并且优于 CoVoST2 到英语翻译零样本的监督 SOTA。

Chan, W.、Park, D.、Lee, C.、Zhang, Y.、Le, Q. 和 Norouzi, M. SpeechStew:只需混合所有可用的语音识别数据来训练一个大型神经网络。arXiv 预印本 arXiv:2104.02133, 2021。??Galvez, D., Diamos, G., Torres, JMC, Achorn, K., Gopi, A., Kanter, D., Lam, M., Mazumder, M., and Reddi, VJ规模多样的英语语音识别数据集用于商业用途。arXiv 预印本 arXiv:2111.09344, 2021。??Chen,G.,Chai,S.,Wang,G.,Du,J.,Zhang,W.-Q.,Weng,C.,Su,D.,Povey,D.,Trmal,J.,Zhang, J.,等人。Gigaspeech:一个不断发展的多域 asr 语料库,具有 10,000 小时的转录音频。arXiv 预印本 arXiv:2106.06909, 2021。??Baevski, A.、Zhou, H.、Mohamed, A. 和 Auli, M. wav2vec 2.0:语音表示的自我监督学习框架。arXiv 预印本 arXiv:2006.11477, 2020。??Baevski, A., Hsu, WN, Conneau, A. 和 Auli, M. Unsu 监督语音识别。神经信息处理系统的进展,34: 27826–27839,2021。??Zhang, Y., Park, DS, Han, W., Qin, J., Gulati, A., Shor, J., Jansen, A., Xu, Y., Huang, Y., Wang, S., et人。BigSSL:探索用于自动语音识别的大规模半监督学习的前沿。arXiv 预印本 arXiv:2109.13226, 2021。??
Whisper已经发布了一段时间,来客观评价一下:
先说大家都能看懂的,Whisper的开源肯定会影响到商业语音识别系统的商业逻辑。
1、Whisper的重要意义在于它Open了。他让大公司和小公司的语音识别系统不再因为小公司没钱标数据而干不过大公司。语音识别系统从标数据又回到了研究一些经典问题,如:热词、Adaptation、Customization等等。而这些技术是对语音识别的用户体验十分重要的,
例如:online开会,我的ASR系统就是可以准确识别参会人人名,以及主题相关的热词。
例如:医疗行业,我的ASR系统就是可以识别疾病名和药名
例如:虽然起跑线一样,我的ASR系统可以灵活的加入Covid-19这种新词。
2、商用语音识别的市场并不会因为这个模型而萎缩。虽然系统开源了,但是如何host,如何streaming等等仍然不是非IT公司雇个人就能给你搞定的。非IT公司仍然要买服务,但是之前可能大公司可以靠数据碾压小公司,现在要回到群雄并起了,回到如何能更好的服务用户了。
3、虽然这个模型好,但是它没法做实时语音识别,所以一个纯伸手党,应该也用这个模型赚不了钱。。。还是要看一下我们之前怎么用Transformer用可控成本做real-time语音识别的论文(手动狗头,夹带私货),finetune一下把模型变得可以实时。Developing Real-Time Streaming Transformer Transducer for Speech Recognition on Large-Scale Dataset
Developing Real-Time Streaming Transformer Transducer for Speech Recognition on Large-Scale Dataset--------------------------------------------------------------------------------------------------
从技术上分析一下:
1、从国外博主测评来看,ASR结果和以后的开源模型差不多。和OpenAI之前的模型相比,这个模型确实不是那么碾压。看了一个测评,和已有的一些数据量和模型大小远小于Whisper的开源系统对比,我们可以看到,NVIDIA的xlarge model (600M)虽然比whisper(1.5B) 小3倍,但是很多集合上的结果好非常多。看所有集合的对比也是半斤八两。我相信以OpenAI的技术能力,下个版本还是做得更好。
和其他闭源系统在一些benchmark比,也不是特别惊艳。所以这项研究并不是CLIP式的研究,这次大力出的奇迹,别人已经看过一次了。
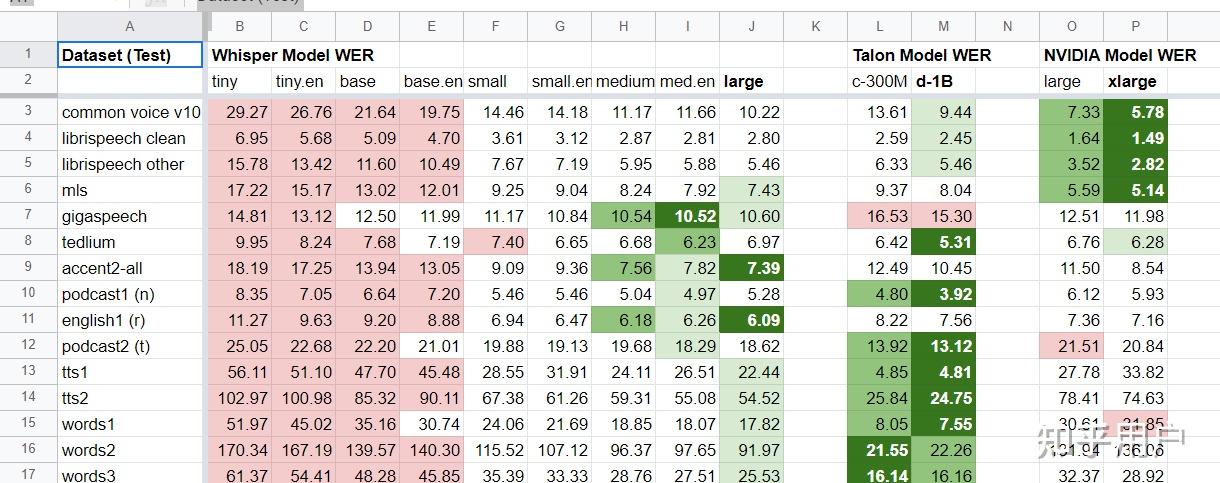 Whisper和其他开源系统比较2、Whisper可能把精力主要放在训大模型。这个base模型和tiny模型感觉训练的有点问题。我相信大部分语音从业者跑过base的setting,也会知道一些librispeech的结果,这个base 4.7/10.49确实有些高了。。。以我之前的经验,即使混一些其他的数据,librispeech结果也不会这么差。。。
Whisper和其他开源系统比较2、Whisper可能把精力主要放在训大模型。这个base模型和tiny模型感觉训练的有点问题。我相信大部分语音从业者跑过base的setting,也会知道一些librispeech的结果,这个base 4.7/10.49确实有些高了。。。以我之前的经验,即使混一些其他的数据,librispeech结果也不会这么差。。。
3、论文的主要卖点很简洁:Speech通过加数据和加大模型,ASR系统可以Robust,不用那些预训练啥的花里胡哨的。这点应该所有从业者都知道,但很多人搞不定数据,那我来帮大家搞定,大家以后都在我这上做二次开发。
最后做个总结,大家可以期待2、3,这个Whisper 1主要的贡献还是开源了个还不错的模型,有一些惊喜也有一些失望。
Whisper是由Open AI训练并开源的语音识别模型,它在英语语音识别方面接近人类水平的鲁棒性和准确性。该模型于2022年9月21日发布之后引起了广大的关注。由于模型的准确性太过惊人,大家已经认为可以直接用于视频的配音制作了。而今天有人发现Whisper的GitHub上有了一个新的提交记录,显示Whisper V2版本即将来临。
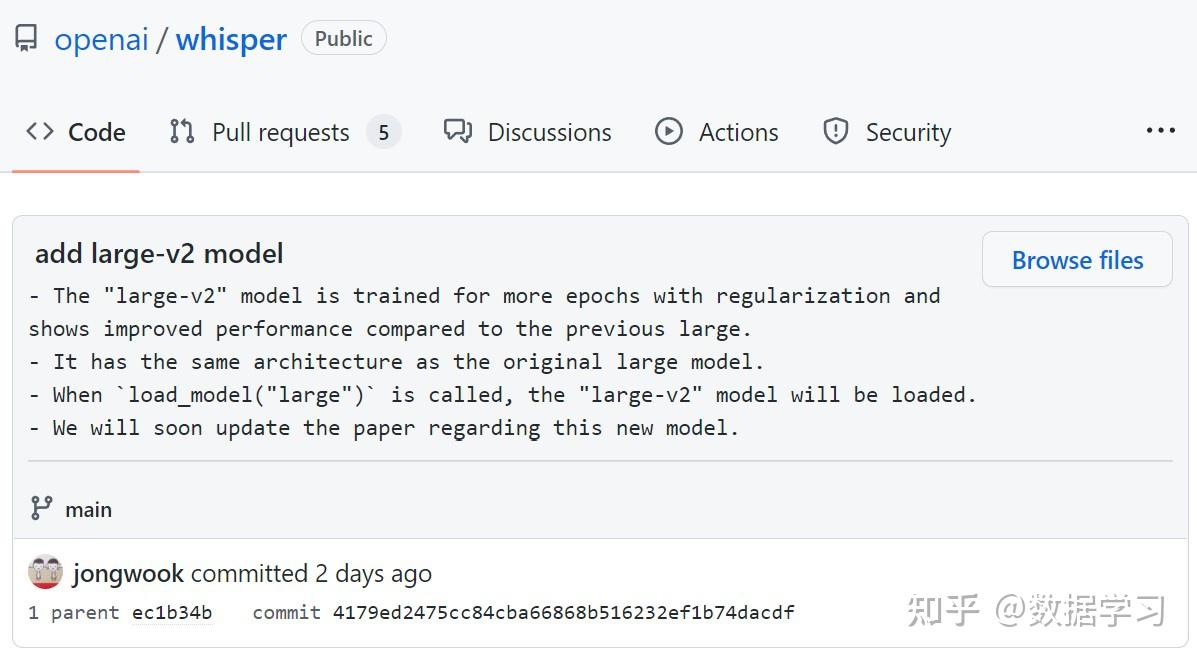
上图显示,V2版本的Whisper模型于第一个版本的结构一样,但是加了正则,且训练的迭代次数更多。这个模型的论文也将很快发布!由于第一版的效果已经很好,这第二版的提升十分令人期待!
Whisper是一个自动语音识别(ASR)系统,它是在从网络上收集的680,000小时的多语言和多任务监督数据上训练出来的。我们表明,使用这样一个庞大而多样的数据集,可以提高对口音、背景噪音和技术语言的稳健性。此外,它还能实现多种语言的转录,以及从这些语言翻译成英语。我们正在开放模型和推理代码,作为建立有用的应用程序和进一步研究稳健语音处理的基础。
关于Whisper的介绍:
Whisper(Whisper)详情 | 数据学习 (DataLearner)
OpenAI 宣布开源多语言语音识别系统 Whisper会有3点改变;改变一:目前市面上大部分的语音识别系统都不具备多语言识别,但是Whisper系统做到了,这点可以帮助我们将语音识别技术应用到更广泛的区域中去;改变二:Whisper能够准确识别进行语音识别的操作,是因为它采用了深度的学习技术,并且,它还能够进行实时语音转写,在输入语音的同时就能准确、快速地识别出内容;改变三:OpenAI的开源也是有好处的,这意味着有更多的人参与到多语言语音技术识别的开发中来,对于技术发展其实也是起到了促进作用,而且开源本身的使用门槛比较低,大部分人也能够轻松享受智能语音交互带来的便利。但是,Whisper系统有利就有弊,对于新手小白或非技术人员来说使用起来是比较困难的;不过大家也不必太过担心,因为市面上其实还有许多操作简单并且容易使用的音频识别工具的,下面就让我分享给大家吧~
WPS是我们办公的好帮手,可以制作和编辑文档、表格、ppt外,其实里面内置的许多小工具还可以帮助我们进行其它操作,例如【音视频转文字】功能。我们只需要在电脑上将软件打开,然后新建一个空白文档,在工具箱中找到【音视频转文字】的功能;选择【音频转文字】,将需要转换的音频文件上传上去,接着选择转写的语言和领域,最后点击【开始转写】等待系统将其转换成文字就好了。
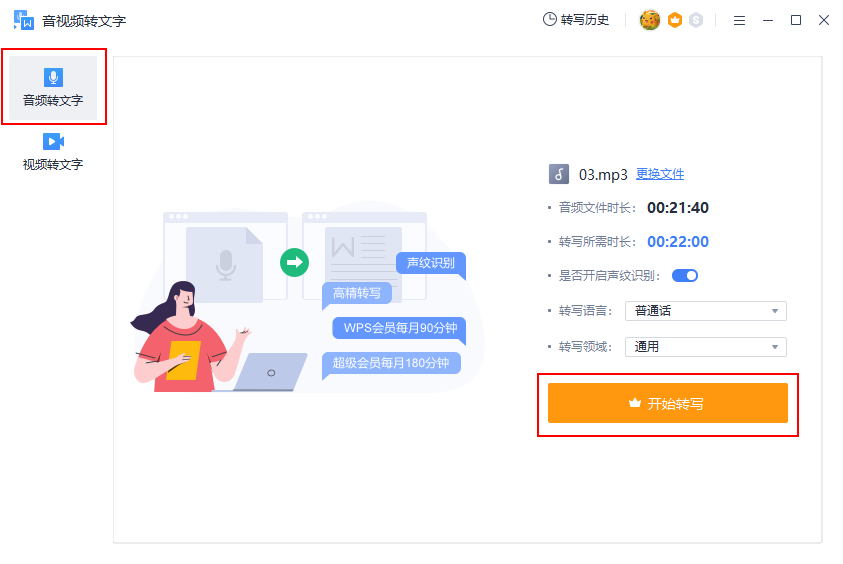 这里要注意一下,该工具需要开通会员才可进行转写喔!
这里要注意一下,该工具需要开通会员才可进行转写喔!
如果你需要经常对各种格式的音频文件进行多方面处理的话,那我建议大家使用这款专业的音频处理软件。该软件支持的音频处理工具非常齐全,包括音频转换、音频剪切、音频转文字、音频合并、文字转语音、音频变声等,而且操作起来很简单,所以初学者也能轻松驾驭。
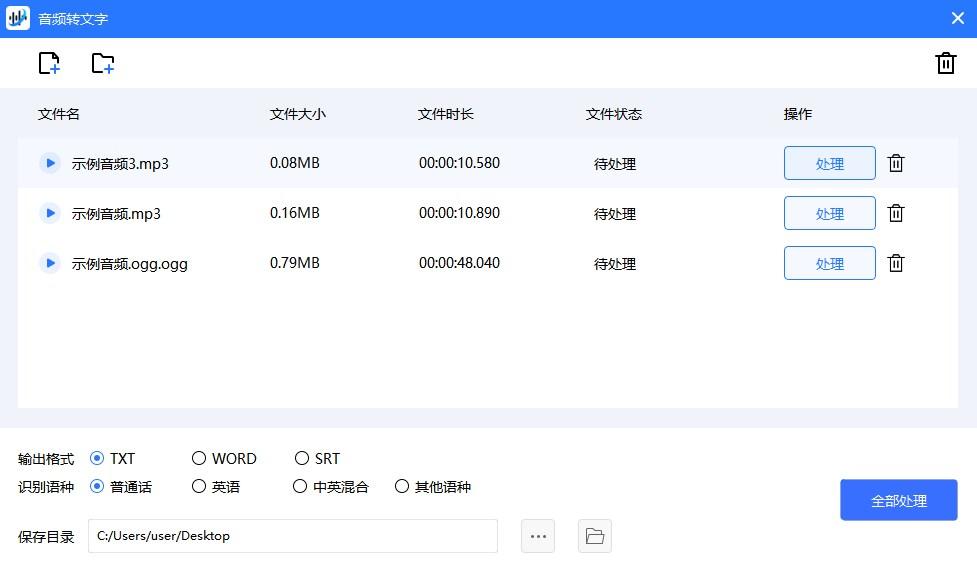
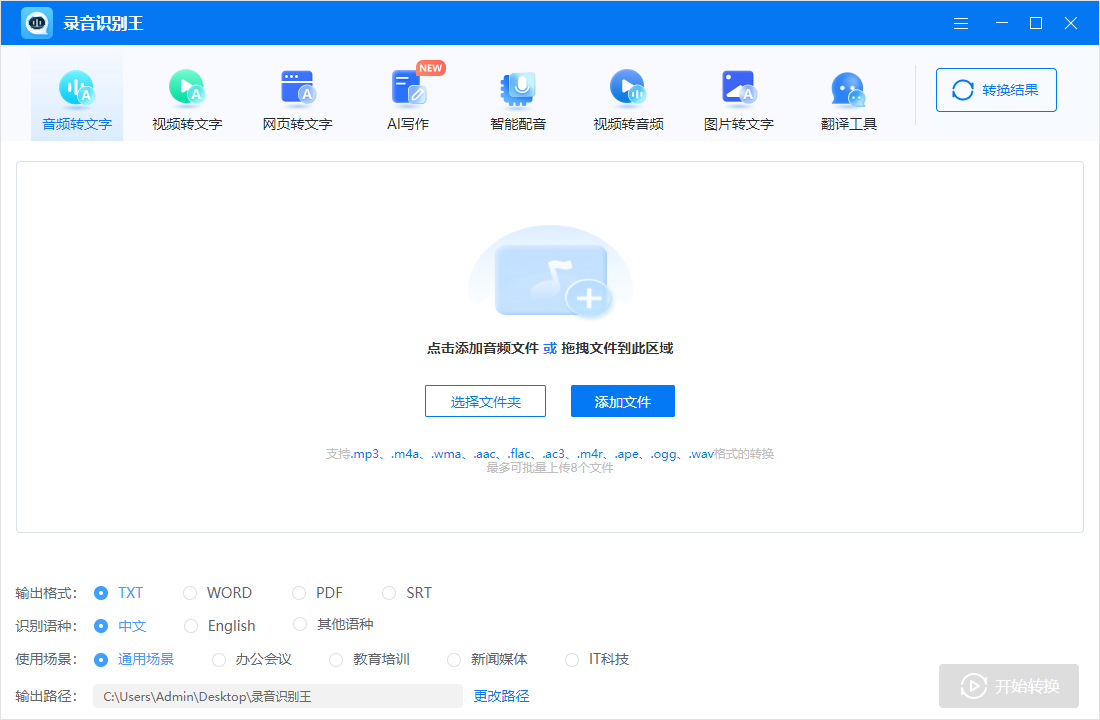
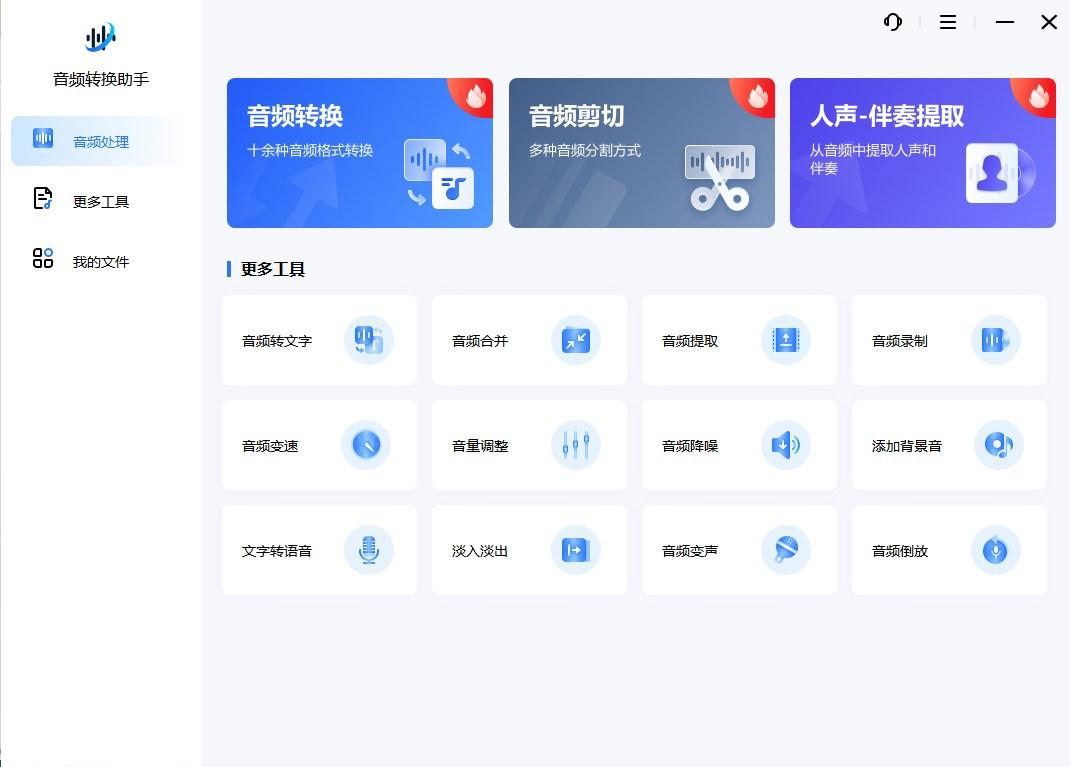 打开软件,点击界面的【音频转文字】功能,将单个或者多个需要转换的文件给添加到里面去;接着在下方选择【输出格式】和【识别语种】后,点击【全部处理】按键等待其自动转换,并把转换成功的文字内容保存在所选的途径中就行啦。
打开软件,点击界面的【音频转文字】功能,将单个或者多个需要转换的文件给添加到里面去;接着在下方选择【输出格式】和【识别语种】后,点击【全部处理】按键等待其自动转换,并把转换成功的文字内容保存在所选的途径中就行啦。
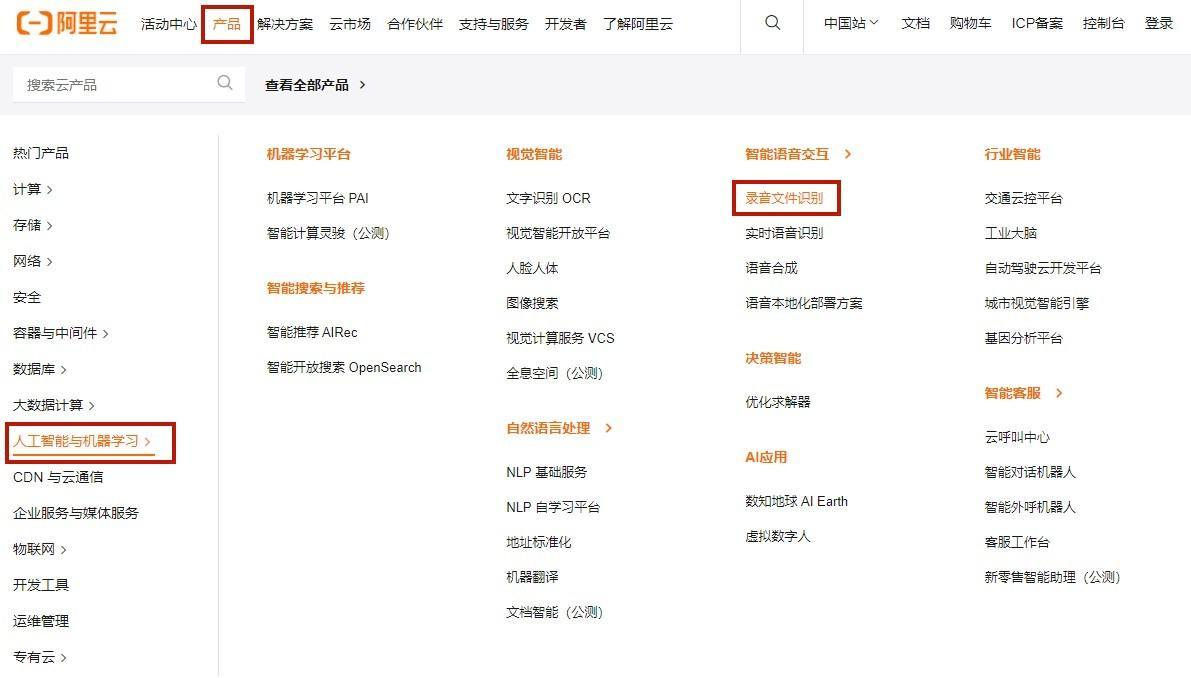
 阿里云是由阿里巴巴推出的云计算服务平台,里面内置许多工具,例如文字识别ocr、录音文件识别、图像搜索、机器翻译等。使用方便,直接在浏览器上搜索就可以进行操作。操作流程很简单,只需点击界面最上方的【产品】里面的【录音文件识别】工具,然后将音频文件添加进去,最后按【开始识别】按钮等待系统识别出文字内容就行了。
阿里云是由阿里巴巴推出的云计算服务平台,里面内置许多工具,例如文字识别ocr、录音文件识别、图像搜索、机器翻译等。使用方便,直接在浏览器上搜索就可以进行操作。操作流程很简单,只需点击界面最上方的【产品】里面的【录音文件识别】工具,然后将音频文件添加进去,最后按【开始识别】按钮等待系统识别出文字内容就行了。
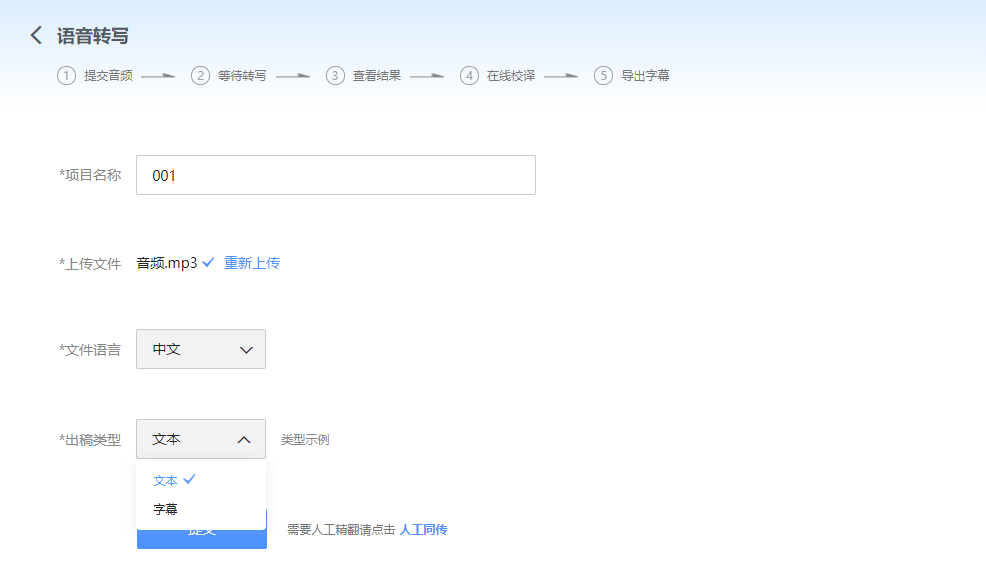
 一个好用的在线转写平台,界面干净简洁,而且非常容易操作。支持语音转写、视频转写、语音翻译、视频翻译、字幕翻译、文档翻译等多种功能,转换的效果也蛮好的。在浏览器上搜索并打开该工具,点击界面右上角的【新建项目】,找到【语音转写】功能;把文件导入进去,选择好转写语言等参数,最后点击【提交】就好了。
一个好用的在线转写平台,界面干净简洁,而且非常容易操作。支持语音转写、视频转写、语音翻译、视频翻译、字幕翻译、文档翻译等多种功能,转换的效果也蛮好的。在浏览器上搜索并打开该工具,点击界面右上角的【新建项目】,找到【语音转写】功能;把文件导入进去,选择好转写语言等参数,最后点击【提交】就好了。
 文章到这里就告一段落,有什么需要修改或者不足之处,欢迎大家评论区批评指点~ @Noah诺亚
文章到这里就告一段落,有什么需要修改或者不足之处,欢迎大家评论区批评指点~ @Noah诺亚
改变的话一共有三点:
①可以提高语音识别技术的稳定性和准确性,Whisper开源可以让我们更加深入的了解语音识别技术的工作原理以及细节。②有利于语音识别行业的发展以及普及,之前因为技术要求高,导致了部分开发者和许多的用户无法进入这个领域,现在各位就可以更加便捷的使用这个技术了。③可以让语音识别技术应用许许多多的不用领域,比如家具、客服、编导等。其实我自己也是经常在使用语音识别功能,无论是以前上大学的时候识别老师的课题,还是现在经常使用语音识别来帮我转换会议纪要,语音识别以及成为我们工作生活的工具之一了。
下面我就给大家分享四款我自己亲测的音频识别软件,有需要的小伙伴们可以收藏自取哦。
这款录音多功能转换软件我还是比较喜欢的,支持双语混合识别语言,拥有转写实时的录音以及导入本地音频进行转写两种模式。
支持英、日、法、德等数十种外语翻译,除此之外也能对我们国内的部分方言进行识别,例如上海话、粤语、四川话等多种方言。
而且处理录音相关功能外,它也是可以帮我们将文本转换成语音。
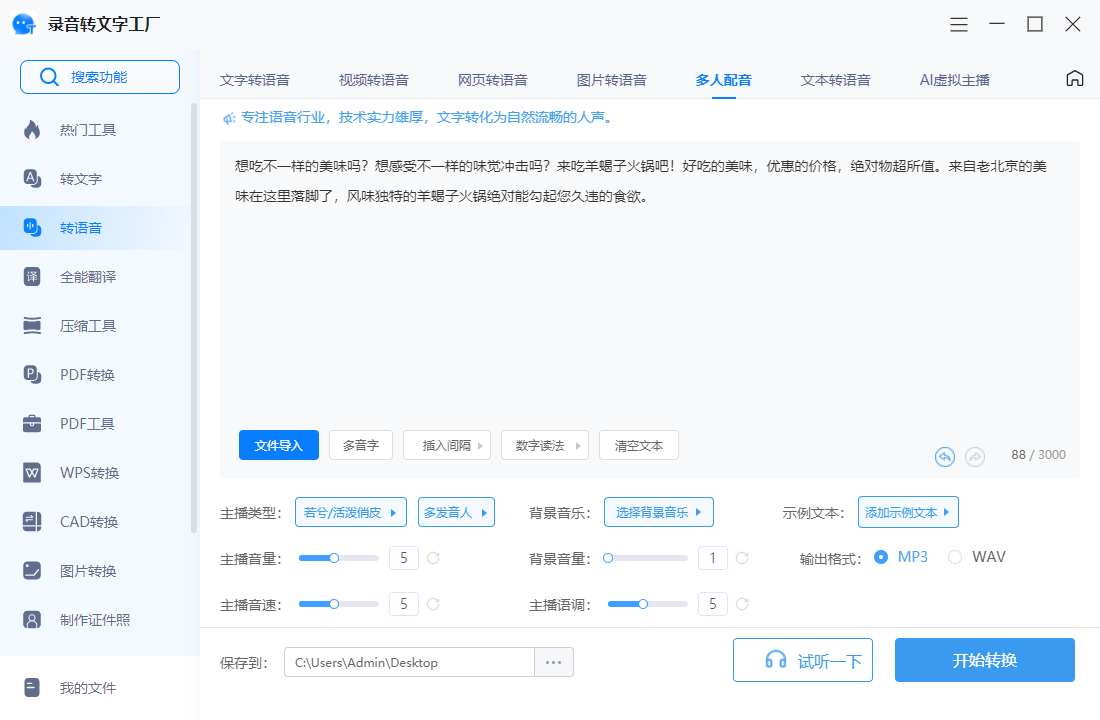
 操作步骤:
操作步骤:
1.操作也十分的简单,打开软件,选择【智能配音】功能:
2.将需要配音的文本添加到指定的区域,选择好语音声线和背景音乐;
3.选择调节声音设置、声音速度、主播语调来使配音更加拟人化。
 一款我们日常工作生活中经常会使用到的办公神器,它的文件文档编辑、演示、转换功能还是一如既往的好用,但是许多小伙伴可能并不知道它其实也是有语音朗读的功能的哦
一款我们日常工作生活中经常会使用到的办公神器,它的文件文档编辑、演示、转换功能还是一如既往的好用,但是许多小伙伴可能并不知道它其实也是有语音朗读的功能的哦
操作步骤如下:
1.打开软件,选择需要朗读的文本;
2.点击右下方的工具栏后选择【语言朗读】即可。
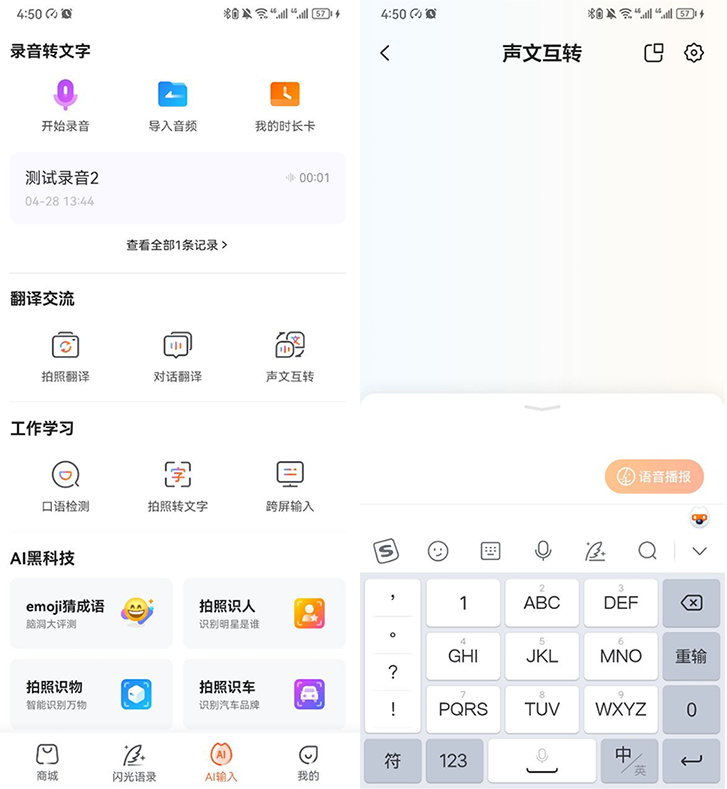
 一款多功能智能输入法软件,各位小伙伴可能没想到在我们日常使用输入法软件里面就有文字转语音功能,而且还附带了许多辅助工具。
一款多功能智能输入法软件,各位小伙伴可能没想到在我们日常使用输入法软件里面就有文字转语音功能,而且还附带了许多辅助工具。
操作步骤如下:
1.打开搜狗输入法,点击【AI输出】界面,选择【声文互转】;
2.然后将需要转语音的文字输入到指定区域即可。
 一款操作简单的语音合成工具能够合成的语言蛮多的,例如常见的英文、法语、德语、西班牙语等等,而且内置多款有趣且特别的朗读音色,一些影视片里面的角色声音它也有提供。
一款操作简单的语音合成工具能够合成的语言蛮多的,例如常见的英文、法语、德语、西班牙语等等,而且内置多款有趣且特别的朗读音色,一些影视片里面的角色声音它也有提供。
操作步骤:
1.打开该合成工具,导入需要转换的文本内容;
2.然后在右侧选择文本语言和一款喜欢的声音音色;
3.最后按【开始转换】按钮,等待片刻就能得到转换后的音频文件了。
 以上就是今天分享的全部内容,希望对大家有所帮助!
以上就是今天分享的全部内容,希望对大家有所帮助!
觉得内容不错的话,就点个赞支持一下啦~
这里是 @协力办公,欢迎大家关注,我会多多分享一些有趣优质的内容!!!