动态网页实战| python爬虫+前端框架Bootstrap
今天我们来爬取动态网页-爬取猫眼电影实时票房数据首先打开猫眼专业版-实时票房可以看到黄色的电影票房一栏是实时更新的。
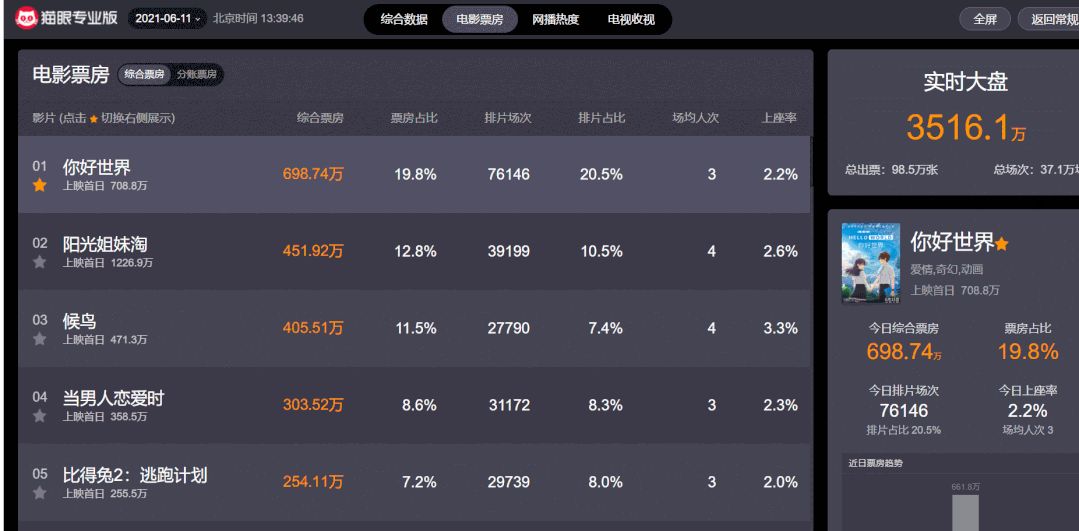
而当我们查看该网页源代码时,却并没有电影相关的票房等信息那么可以判断该页面可能使用了 Ajax(即“Asynchronous Javascript And XML”(异步 JavaScript 和 XML))技术,即动态网页(是指跟静态网页相对的一种网页编程技术。

静态网页,随着html代码的生成,页面的内容和显示效果就基本上不会发生变化了——除非你修改页面代码。而动态网页则不然,页面代码虽然没有变但是显示的内容却是可以随着时间、环境或者数据库操作的结果而发生改变)。我们可以利用浏览器的开发者工具进行分析:
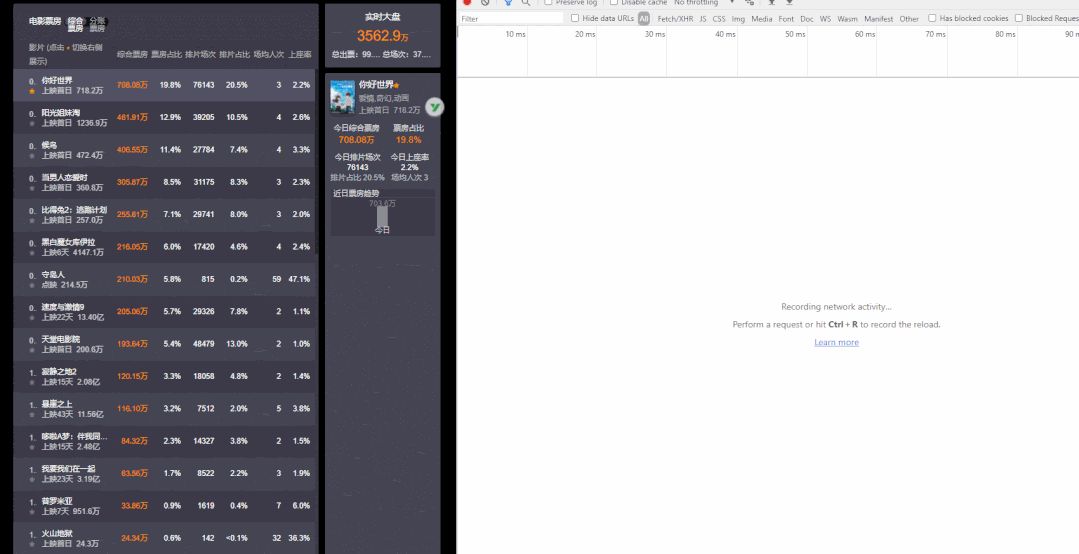
我们可以发现每隔一段时间都会有一个新的请求,其请求类型都为 xhr,而 Ajax 的请求类型就是 xhr,这请求可能就是实时更新的票房信息,而我们需要的数据可能就在这些文件里,于是我们选择一个进行分析:
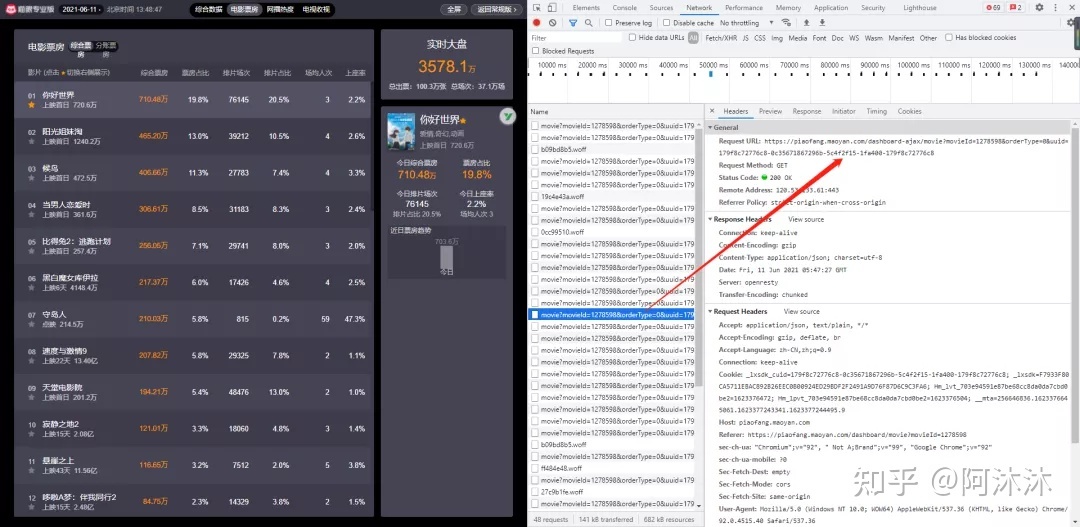
复制链接打开可以发现这是一个json格式的数据。

我们想要获取的信息
都包含在list里面。所以第一步,先获取所有电影信息
可以看到已经成功的获取到了全部的影片信息。
获取对应的 JSON 数据后,下面对该 JSON 数据进行提取:
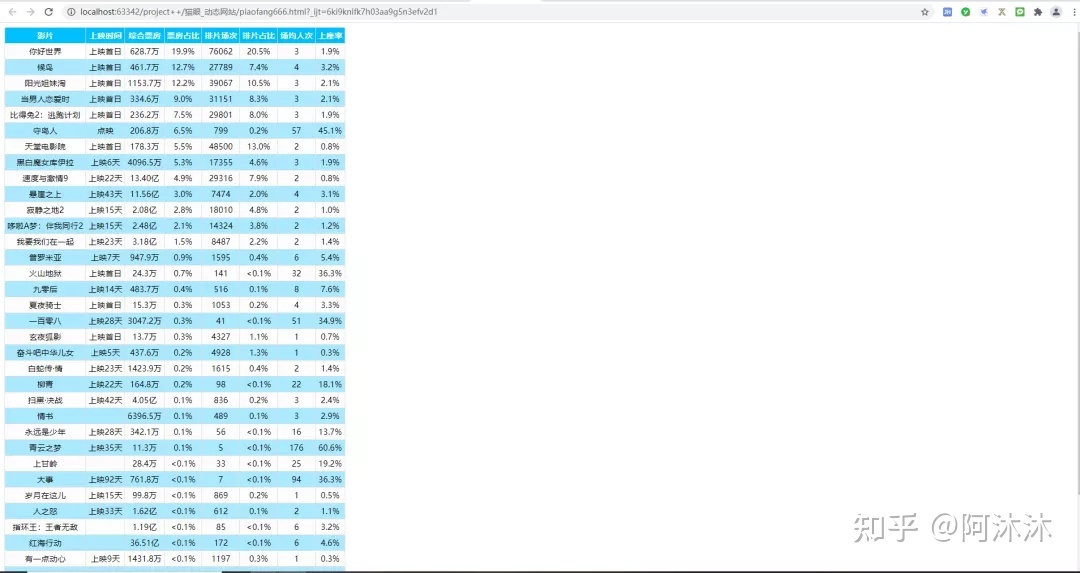
接下来我们就将提取好的票房信息存储为格式化的 HTML 文件:
浏览器打开生成的piaofang.html页面这页面丑的跟我一样,不忍直视啊!
我记得前端框架Bootstrap里面有好多的排版和样式,咱们一起去瞅瞅传送门:
我们随便选一个
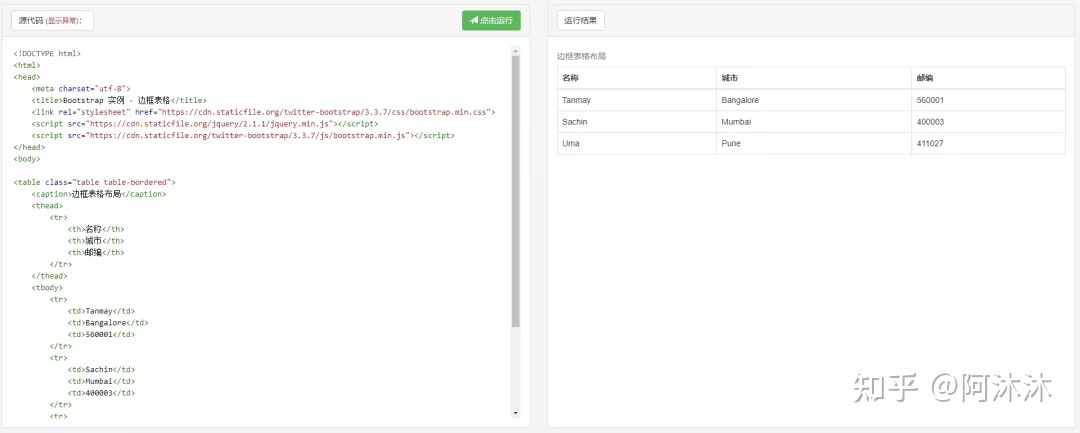
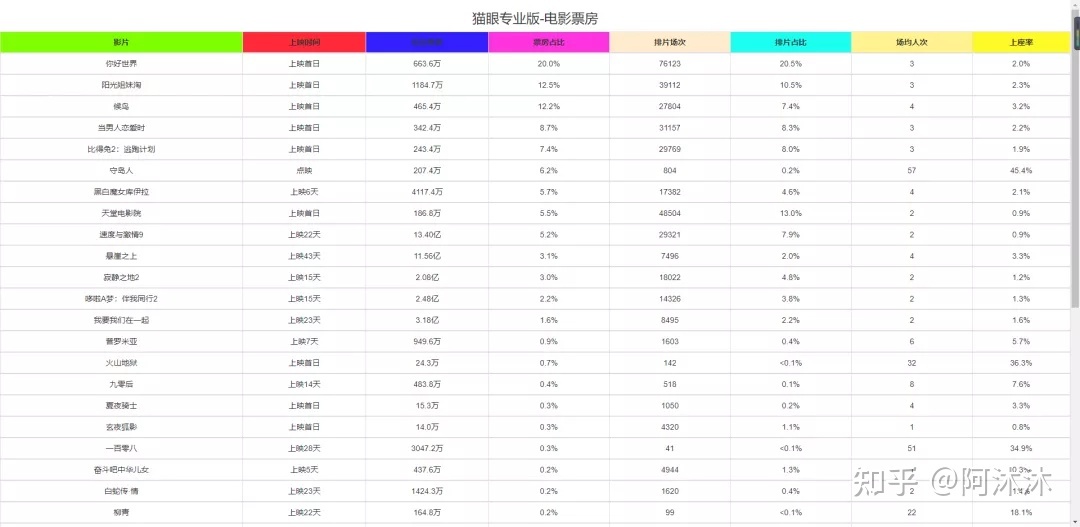
导入我们爬虫获取到的数据,最后的页面就是这个样子的。
或者是这个样子的
就酱紫。。。你也可以根据自己的需要给它加上颜色啦、改变字体啦、添加背景图片啦等等。目的只有一个,让你的页面更具有吸引力!