换脸方法之FaceShifter

2019年,国外论坛的,大表姐珍妮佛劳伦丝和史蒂夫布什密通过Deepfake技术的实时换脸视频。
链接:https://www.youtube.com/watch?v=iHv6Q9ychnA
论文:FaceShifter: Towards High Fidelity And Occlusion Aware Face Swapping
github:https://github.com/taotaonice/FaceShifter

论文提出了一个基于2阶段的GAN方式的换脸方法FaceShifter。整体网络结构包含,AEI-Net ,HEAR-Net两个网络。FaceShifter通过获取输入的2个图片中,第一张图片的ID特征,第二张图片的属性特征,来通过GAN生成最终的合成图片。合成的图片具有第一个图片的ID特征,第二个图片的属性特征,从而实现了换脸,并且取得了目前state-of-the-art的效果。
换脸的相关方法:
基于3d的方法,3D-Based Approaches 包括,3DMM,Face2Face
2. 基于GAN的方法,GAN-Based Approaches
包括,CageNet,SwiftNet,DeepFakes,RSGAN,FSNet,IPGAN,FSGAN
FaceShifter结构:

Adaptive Embedding Integration Network (AEINet):

网络输入图片为256*256,训练数据从CelebA-HQ,FFHQ,VGGFace这3个数据集中获取得到。
AAD部分,加权attention方式融合了ID特征和Attributes特征。多个AAD+Relu+Conv堆叠,形成了AAD ResBlk模块。多个AAD ResBlk的组合,形成了最终的AEINet。
AEINet包括3个部分,
身份ID编码模块,Identity Encoder 该模块是一个已经训练好的人脸识别模块,即Archface模块。在整个网络中,该模块只进行前向传递,不进行loss回传训练。
2. 属性ATTRIBUTES编码模块,Multi-level Attributes Encoder,属性包括姿势,表情,光照,背景等(pose, expression, lighting and background)。
该模块的网络结构是一个U-Net形状的结构。有助于编码不同层的属性特征。
![]()
其中,n=8,一共编码了8个分支的特征。
该阶段的训练,不需要任何属性的标签进行监督训练,整个过程完全是无监督的方式进行训练学习。
那么问题来了,没有属性标签进行约束,那么这个模块是怎么按照作者设计的意愿,去学习人脸的属性特征呢?
这个问题讲到这里就回答,其实不合适,但是还是得提前剧透。
整个网络的训练过程是随机的输入2组图片进行,而这2组图片是从数据集中随机取到的。可能是同样的人,也可能不是。而采样中,作者控制了同样的人的概率是80%。不同人的概率只有20%。如果是网络的输入是2个同样的人,那么网络的输出肯定也还是同样的人。而ID编码网络部分是提前训练好的,不参与训练。也就是说ID编码模块肯定是学习的人脸的ID特征。假设人脸特征=ID特征+attributes特征,要保证最终合成的图片还是那个原来的人,那么attributes编码模块就只能学习属性特征。就是通过这样的方式,来实现无监督的让attributes编码网络自动学习属性特征。所以也需要80%这样相对大的概率,来保证该模块的收敛。这也就是本方法的一个亮点。试想,如果整个训练全部都是不同的人的组合,那肯定是学习不出这个网络模块的。这个可以自己训练的时候调节这个比例尝试。
3. 融合ID和ATTRIBUTES,并且生成人脸的模块,也就是GAN的生成器部分,Adaptive Attentional Denormalization (AAD) Generator
AAD部分的输入包括2个部分,分别是ID部分和Attributes部分。
Attributes部分的输入为2个属性输出的加权,
![]()
ID部分的输入也是2个ID输出的加权,
![]()
AAD部分进行了基于attention方式的ID和Attributes的加权融合。
首先AAD模块对前一层的输入进行conv降维+sigmoid归一化操作,得到1个0-1的特征图,然后使用该特征图进行ID和Attributes的融合。
![]()
AEINet的loss包括4部分,分别为
GAN的判别器的loss Ladv,也就是AAD生成的图片,判别器判断是真实图片还是造的图片的loss。
ID模块的loss,Lid,也就是cos loss,将AAD生成的图片输入ID模块,得到输出特征,然后和之前的输入Xsource的输出特征计算cos距离,保证2个特征相似。
![]()
属性模块的loss,Latt,也就是L2范数,将AAD生成的图片输入Attributes模块,得到输出的特征图,计算其和原始输入Xtarget的L2距离。
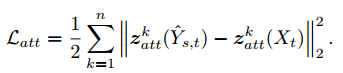
识别的loss,Lrec,该loss只有在输入的2张图片Xsource==Xtarget的时候,才会有loss,也就是AAD的输出和输入Xtarget的L2 loss。其余时刻,该loss为0
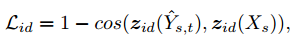
最终AEINet模块的loss为LAEI-NET
![]()
Heuristic Error Acknowledging Refinement Network(HEAR-Net)

HEAR-Net也是一个U-Net类型的网络结构。U-Net的取特征的分支n=5。
前面的AEINet生成的换脸图片虽然可以处理背景,光照,姿势,表情等问题。但是却处理不了遮挡问题。为此,论文引入了HEAR-Net。
同时,作者发现一个现象,当AEI-Net的连个输入图片都相同的时候,得到的生成图片也会吧遮挡部分给去掉。
we observe that if we feed the same image as both the source and target images into a well trained AEI-Net, these occlusions would also disappear in the reconstructed image.
为了恢复遮挡部分,可以使用原始的输入Xtarget和AEI-Net的生成图片作差,得到遮挡部分的特征图?Yt。
![]()
然后使用AEI-Net的输出Y^st和遮挡部分的特征?Yt,经过HEAR-Net生成最终的换脸图片Yst。
![]()
HEAR-Net的loss,包含3部分,
(1)ID部分的loss,同样还是cos loss
![]()
(2)第一个stage AEI-Net和第二个stage HEAR-Net的生成换脸照片的连续性保证的loss。
![]()
(3)只有输入的2个图片相同的时候Xsource==Xtarget,才会有的重建loss,保证重建的图片和输入的图片一样。
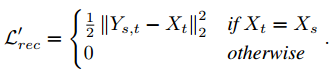
最终,HEAR-Net的loss为,
![]()
详细网络结构:

实验结果:

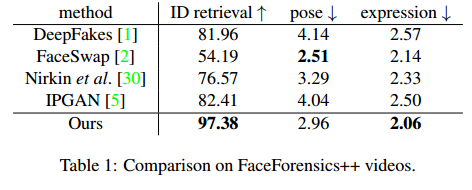
DeepFake vs FaceShifter:
DeepFake
FaceShifter
模型结构
Encoder+Decoder生成模型
GAN,设计了属性提取器和身份提取器提取特征,设计了嵌入器去组合特征。
属性保持
较好
较好
图片质量
一般
较好
可拓展性
差
好
改进思路:
(1)判别器部分,增加随机归一化SN操作,参考,GitHub - godisboy/SN-GAN: pyTorch implementation of Spectral Normalization for Generative Adversarial Networks
(2)对人脸识别模块arcface的输出Yst进行人脸区域的mask操作,然后再与输入Xs进行相似度计算,参考,GitHub - zllrunning/face-parsing.PyTorch: Using modified BiSeNet for face parsing in PyTorch

总结:
FaceShifter 可以对任意2个没有见过的人脸进行换脸。而DeepFakes只能对训练中已经“见过”的人脸进行合成,不具备外插能力。这也成了限制DeepFakes算法商用的重要原因。FaceShifter对保身份和保属性的能力不错,生成图片质量也还可以。FaceShifter设计了一些针对有遮挡、大角度的脸的处理方法,所以有不错的处理遮挡、大角度等极端情况的目标人脸的能力。